A fu*k-up story: The Voice Agent That Debugged Itself
Hi, I'm Jan. I'm a Tech-Lead @webscopeio and I'm taking a leap into the startup world with hire.dev app.
I spend most of my time in front-end engineering. When I'm not programming, I work on hire.dev app.
I'm active daily on Twitter @jankoritak! See you there!
The call you don't want on Friday
The message came in on a Friday afternoon. The voice agent we'd shipped for a B2B client working in the restaurant business, running smoothly for a couple of months, had started regressing. Wrong answers, broken ordering flows, behavior that used to work "reliably" (at least we thought so) now falling apart in ways that were hard to describe, but unfortunately, not that hard to reproduce.
Example from production
Customer: Hi, i would like to order 2 homestyle sandwiches with fries no pickles and california cobb in blazin sauce.
Agent: Got it, I got 8 bbq sandwiches and a crunch milkshake. Anything else?
Oh boy ... you probably see the severity of the situation. If not, let me expand.
Expected:
2× Homestyle Sandwich w/ fries, no pickles + 1× California Cobb w/ blazin sauce → 3 items, ~32€
Got:
8× BBQ Sandwich + 1× Crunch Milkshake → 9 items, wrong menu items entirely, ~95€
We set ourselves a deadline: two days to fix it.
The first thing we checked was the code. No recent changes, no prompt edits, no tool edits, no infra updates, no new deployments. The codebase was exactly where we'd left it.
The last commit touching the voice agent was aa61f03 on 9.3.2026. (today is 30.3.2026)
To give you a sense of the timeline, that's 21 days of no changes.
Which meant the problem wasn't caused by our own immediate actions.
This was also our first voice agent delivery. We'd made a lot of decisions early on that felt reasonable at the time. A chaotic but functional system prompt, a model tested only manually, and infrastructure choices optimized for speed over robustness. Classic first-version tradeoffs. We didn't fully know what we didn't know.
The stack:
| Layer | Provider | Detail |
|---|---|---|
| Speech (STT + TTS + orchestration) | Deepgram Voice Agent | nova-3 STT, managed agent loop |
| LLM | OpenAI via Deepgram proxy | gpt-4o-mini (alias, no version pin) |
| Compute | Hetzner VPS | CPX21 |
| Storage + vector search | Supabase | pgvector, 768-dim embeddings |
| Session state | Redis | Cart, message history, call records |
| Telephony | Twilio | Media Streams over WebSocket |
For a client on a tight budget, a solid setup for a fast MVP. Also our first experience shipping a voice agent end-to-end. Everything is running on third-party providers we didn't control.
That last part was about to become very relevant.
Enter new term: model drift
We hadn't heard the term before this incident, but it has a name: model drift.
In classical ML, drift refers to your input data distribution shifting over time. The world changes, your model doesn't, performance degrades. What we experienced was a variation of that, specific to building on closed third-party AI APIs. Deepgram and OpenAI both update their models continuously. No guaranteed announcement, no changelog in your inbox, no version pin unless you explicitly ask for it. One day, the model behaves one way. The next time, it behaves slightly differently. Your code didn't change. The upstream did.
This is an underappreciated risk (for agencies) shipping AI products. When you own the model, you own the regression. When a vendor owns the model, you can still get the regression. You just don't get the heads up.
Our entry hypothesis was that Deepgram drifted. We couldn't prove it. We still can't. But it was where we looked first, and it shaped the moves that followed.
OpenAI was the second suspect. GPT-4o-mini's behavior on our specific prompts and tool definitions could have quietly shifted without us knowing. Again, impossible to prove definitively. What we did know was that something had changed upstream, it was affecting the agent end-to-end, and we had two days to fix it, regardless of whose fault it was.
The first instinct: Roll back the LLM version
The obvious move was to go back in time. If the model had drifted, pin it to whatever version was running when things worked.
We dug into what version pinning actually looked like for our stack. On the OpenAI side, GPT-4o-mini only ever had one dated snapshot: gpt-4o-mini-2024-07-18. The alias gpt-4o-mini points to that same snapshot. OpenAI-side drift could not be the culprit here. Unlike GPT-4o, which accumulated multiple dated snapshots over time, GPT-4o-mini never got additional ones. You can pin it explicitly:
json
{
"model": "gpt-4o-mini-2024-07-18"
}
But on the Deepgram side, the picture was different. Deepgram's managed voice agent only exposes gpt-4o-mini as a model string. No dated snapshots available. When Deepgram proxies the call to OpenAI, you don't control which version their alias resolves to on their side. There's a BYOK escape hatch:
json
"think": {
"provider": {
"type": "open_ai",
"model": "gpt-4o-mini-2024-07-18",
"temperature": 0.1
},
"endpoint": {
"url": "https://api.openai.com/v1/chat/completions",
"headers": {
"authorization": "Bearer sk-..."
}
}
}
But this realization also pointed to the more likely culprit: not OpenAI's model, but Deepgram's proxy layer. Something in their managed stack (STT, TTS, or the orchestration in between) had quietly shifted. And there was no version to roll back to on that side at all.
Dead end. Time for a different approach.
| Layer | Can you pin a version? | What's exposed |
|---|---|---|
| OpenAI direct API | Yes | gpt-4o-mini-2024-07-18 (only snapshot ever released) |
| OpenAI via Deepgram BYOK | Partial | You pass a model string, but DG orchestration is opaque |
| Deepgram STT | No | nova-3 — no dated snapshots |
| Deepgram Voice Agent loop | No | No version string at all |
The nuclear option
With no version to roll back to, we made a bet.
The idea was simple and a little reckless:
Can we one-shot replace the entire Deepgram core with CC + Opus?
Spin up OpenAI's Realtime API as a replacement, let Claude Code do the heavy lifting of the migration, and see how far we get in a single session.
The answer was:
pretty far, but not far enough.
The swap itself worked. We managed to create a pretty clean adapter architecture, where we can basically use whatever voice agent as the replaceable core (OpenAI Real Time, new Grok Voice Agent, ...). The agent was functional on OpenAI Realtime, a native speech-to-speech solution that collapses STT, LLM, and TTS into one model. But it immediately exposed gaps we hadn't accounted for. Barge-in, the ability for a caller to interrupt the agent mid-sentence, was missing. We were seeing packet loss with Twilio. The conversational smoothness was noticeably rougher than what Deepgram's managed stack had been delivering. For a restaurant ordering agent where natural back-and-forth matters, these are all deal-breakers.
The second attempt went further: stitch Deepgram STT, OpenAI LLM, and Deepgram TTS into our own pipeline, own every layer. This one actually worked. We solved barge-in with transcript-based interruption, ignoring Deepgram'sSpeechStarted events (which fire on echo and background noise) and only interrupting on real transcribed words.
With these new findings. We fell back to Deepgram Voice Agent. The managed stack handled turn detection, audio buffering, and silence thresholds with a smoothness we couldn't match in a weekend. Our stitched pipeline was functional. Theirs felt more natural. We had limited time.
The lesson wasn't that we couldn't build it. It's that managed voice abstractions earn their keep, and knowing that because you tried is different from assuming it because you didn't. Audio buffering, turn detection, and interruption handling, we got it all working, but the polish gap was real.
We stepped back. We needed a smarter strategy.
Building a test harness
Before we could fix anything properly, we needed to be able to measure success.
Up to this point, we'd been flying on intuition. Making a change, manually calling the agent, deciding if it felt better. That works once. It doesn't work when you're trying to converge on reliable behavior across a dozen different scenarios, each with its own tool calls, ordering flows, and edge cases. We needed a harness.
The foundation was client-sourced scenarios. We sat with the client and worked through the real calls their agent was expected to handle:
Ordering meals
Asking about the menu
Checking opening hours
Making reservations
Handling modifications
FAQ questions
... you name it
Each scenario became a structured test case: a defined input, a sequence of expected tool calls, and an expected output.
You may be familiar with tools like Hamming test to determine whether the agent sounds right for persona, latency, sentiment, and compliance. We needed to test whether the agent did the right thing.
Did it call
cart_add_itemwith the correct UUID?Did it remove the mozzarella sticks before adding the buffalo dip?
Does the Redis cart state match what the agent told the customer?
Different layer entirely.
Call flow correctness first. Everything else second.
A sourced scenario from the client:
C: hi i would like to get hot honey sandwich with fries no ranch, mozzarella sticks tossed in hot honey sauce and strawberry field salad no feta crumbles
A: okay got it, anything else?
C: yes add korean bbq sandwich
A: okay got it, anything else?
C: actually remove the mozzarella sticks
A: okay got it, anything else?
C: yes add cinnamon toast crunch milkshake
A: okay got it, anything else?
C: no that’s it
A: what is your name?
C: John Doe
A: can i use this phone number or would you like to use different one?
C: this number is fine
A: okay i got hot honey sandwich with fries no ranch, strawberry field salad no feta crumbles, korean bbq sandwich and cinnamon toast crunch milkshake, your total is 41€ and you can pick it up in about 25 min.
Can i help with anything else?
C: that’s all
A: ends the call
The test scenario is rich, but let me paint the picture with a piece of mozzarella.
# Replace mozzarella sticks with buffalo chicken dip — tests removal + re-add
- user: "Actually, swap the mozzarella sticks for the cheesy buffalo chicken dip"
expect_tool_calls:
- name: cart_remove_item
args:
menu_item_id: { contains: "house-mozzarella-sticks" }
- name: cart_add_item
args:
items:
items_contain:
- menu_item_id: { contains: "cheesy-buffalo-chicken-dip" }
quantity: 1
expect_no_tool_calls: [end_call]
Simple as that.
By now, we had built a few providers, so we built the harness to be provider-agnostic from day one. The same scenarios could run against any strategy. At that time, we had three:
deepgram-voice-agent-gpt-4o-minideepgram-voice-agent-gpt-5.4-minideepgram-stitched-stt-llm-tts-gpt-5.4-mini
This turned out to be one of the best decisions of the whole weekend. Every time we tried a new approach, we had a performance score within minutes.
We started with 15 thorough scenarios.
| # | Name | Status |
|---|---|---|
| 01 | simple_three_items | PASS |
| 02 | medium_mods_and_sides | FAIL |
| 03 | hard_mods_and_removal | FAIL |
| 05 | simple_sandwich_and_dip | PASS |
| 06 | simple_sandwich_and_milkshake | PASS |
| 07 | medium_mods_sides_and_shake | FAIL |
| 08 | medium_wings_salad_and_shake | FAIL |
| 09 | hard_removal_and_milkshake | FAIL |
| 10 | hard_sauce_change_and_shrimp | FAIL |
| 11 | hard_cart_integrity_quantity_and_removal | FAIL |
| 12 | hard_cart_integrity_item_identity | FAIL |
| 13 | hard_modifications_preserved | FAIL |
| 14 | hard_quantity_stress_test | FAIL |
Baseline with the deepgram-voice-agent-gpt-4o-mini The provider was 3 out of 14 scenarios passing. Oh boy.
That number was clarifying. We weren't dealing with minor behavioral drift. The agent was fundamentally broken across most of its core flows. And now, for the first time, we could see exactly which ones.
Testing a simple hypothesis first
Before unleashing an autonomous loop on the problem, we tried an obvious lever: just swap the model.
The nuclear option had failed. Swapping the entire core was too disruptive. Deepgram Voice Agent brings a lot of value. What about staying on Deepgram's managed stack and simply switching the LLM underneath it? We moved from GPT-4o-mini to GPT-5.4-mini via BYOK. Same Deepgram architecture, different brain.
New score.
5/13 passing
Scores went up slightly, but failures were still present across most scenarios. The two new passes were both medium-complexity ordering flows. Every hard scenario, including removals, modifications, quantity stress, still failed. The model swap alone wasn't enough. The regression wasn't purely a model quality issue. The entire configuration around it, the system prompt, the tool definitions, the agent architecture, all of it had accumulated enough technical debt from our first-version mistakes that no single model change was going to fix it.
This was actually an important moment. In the past, we would have started tweaking the prompt manually, making changes based on intuition, testing by calling the agent. A slow, imprecise process with no real feedback loop. But now we had the harness. Every change produced a score. Every failure pointed to a specific scenario. We weren't flying blind anymore.
Karpathy's Auto-Research Pattern & Letting the Agent Fix the Agent
At this point, we had a score, a failing test suite, and a clear problem: the entire configuration needed work.
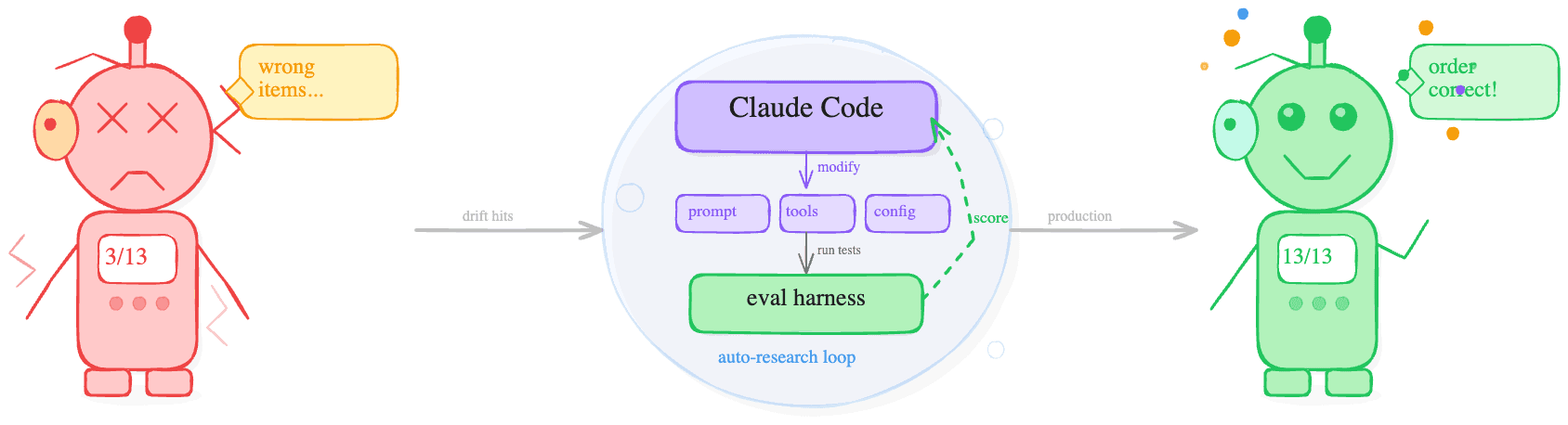
Andrej Karpathy's auto-research pattern on GitHub is a simple but powerful idea: give an autonomous agent a goal, a feedback signal, and permission to modify its own configuration, then let it loop until it (hopefully) converges. No human in the loop for each iteration. You define the success criteria, and the agent does the tuning.
Adapted to our situation:
Claude Code in auto mode became the engine
Feedback signal was the eval harness (a numeric score after every run)
The scope of what it could touch was deliberately broad:
The system prompt
Tool descriptions
Tool implementations
The structure and configuration of the voice agent provider itself.
We were letting the agent rethink itself, end-to-end.
A few things we learned quickly about what made the loop work:
Encourage general adjustments, rather than patching undesired behavior. Early in the loop, there's a temptation to fix individual failing scenarios directly. That leads to overfitting. The better instruction is to look for systemic issues like prompt structure, missing rules, and ambiguous tool boundaries. Specific scenarios improve as a byproduct.
When the agent failed scenario 08 (wings + salad + shake), it was recapping items before the customer finished ordering.
We obviously didn't add "don't recap after wings."
We added a general rule: only recap when the customer signals they're done.
Tool descriptions are architecture, not documentation. GPT-4o-mini was getting stuck in loops, unable to decide which tool to call. The fix wasn't a better model. It was rewriting tool descriptions to be clean, unambiguous mappings. No conditional logic inside a description. No "if the user asks X, use this tool." Just a precise, concise statement of what the tool does and when to use it. The LLM needs to pattern-match to a tool, not reason its way to one. This single change had an outsized impact on tool call reliability.
- get_menu: Search the restaurant menu for items.
+ get_menu: Search the restaurant menu by keyword. Returns matching
+ items with id, name, price, and category. For multiple items, use
+ comma-separated terms. Use categories_only=true when the customer
+ wants to browse without searching for a specific item.
The results were immediate. From 2/13, we started climbing 4, 5, 6, 7 passing scenarios across successive iterations. The loop was working.
The Restructured Prompt: Two Philosophies Emerge
As the agentic loop iterated, something unexpected happened. We ended up with two fundamentally different approaches (prompts). And both were working.
Organic prompt
The first was the organic prompt. This was the prompt we initially built. It had evolved through the loop. Patched, extended, battle-tested against the eval suite. It was chaotic in structure, hard to read if you hadn't lived through its evolution, but it performed. The agent using it felt natural, conversational, a little unpredictable in the best way.
Structured XML prompt
The second emerged from a deliberate decision to start fresh with structure. We rewrote the prompt from scratch using an XML-based state machine approach with explicit sections for <identity>, <rules>, <states>, and <examples>.
Every tool has an explicit "when to use / when NOT to use" block, following OpenAI and Anthropic's own guidance on tool description design. The prompt ended up about 13% smaller than the original despite being more explicit, because the structure eliminated a lot of the redundant, defensive prose that accumulates in evolved prompts.
We also targeted the failure modes we'd identified from the harness directly:
Order finalization skip (~30% failure rate): Fixed with an explicit
CONFIRMINGphase requiring the agent to wait for a customer, yes, before callingcreate_ordertool call.UUID hallucination (~10%): Tool description now instructs the model to verify UUID, name, and price match before calling cart tools.
Add-on vs notes confusion (~15%): dedicated rule with a "why" explanation rather than just an instruction
The agentic loop ran five iterations against this restructured prompt. Baseline was 11/13. After tuning: three consecutive 13/13 runs.
| Organic | Restructured XML | |
|---|---|---|
| Tokens | ~1,500 | ~1,300 |
| Structure | Natural-language rules, evolved through iteration | <identity>, <rules>, <states>, <examples> |
| Eval score | 13/13 (7/8 runs) | 13/13 (7/8 runs) |
| Personality | Conversational, unpredictable | Consistent, methodical |
Two prompts, nearly identical scores, completely different philosophies. We kept both.
The Overfitting Trap: When 100% Means You Broke It
We asked the client for more scenarios. More coverage, more edge cases, more confidence. Obviously a sound move.
It wasn't. Or at least, not without adjusting how we evaluated them.
As we added scenarios and kept running the agentic loop, both prompts started hitting 100% on the eval suite.
And the surprise? The agent got worse. Responses became rigid and mechanical. The conversational flow that had made the original MVP feel natural was gone. The agent was passing every test like a champ, yet failing the actual job.
This is a classic ML problem applied to an unfamiliar domain. When your eval set becomes too specific, your model (or in this case, your prompt) starts optimizing for the tests rather than the behavior. The eval set had become the enemy.
The first fix was the harness itself. We'd been using keyword and phrase matching for text assertions. We've been checking whether the agent's response contained specific strings.
That works for tool calls, where correctness is binary. It doesn't work for conversational text, where the same intent can be expressed a hundred different ways. Replacing contains_any: ["anything else"] With a semantic intent check, the unlock:
# Before — too rigid
expect_text:
contains_any: ["anything else"]
# After — semantic
expect_text:
intent:
- "asks if the customer wants anything else"
We wired this to gpt-4.1-nano as a lightweight judge. It's cheap enough to run on every eval iteration, smart enough to evaluate intent accurately. Tool call assertions stayed hard and exact. Only text assertions went semantic. About 3,000 tokens per full eval run.
We validated the judge against ~30 assertion checks across a full eval run. One false negative, and it was a real flow error the agent made, not a judgment mistake.
The second fix was temperature. We loosened it back up from 0.1 to 0.2. The loop had been converging toward determinism, which felt safe but was producing an agent that couldn't handle anything outside the exact scenarios it had been tuned on.
After both changes, the restructured prompt went from 1/13 to 12/13. The agent felt like itself again.
The lesson: your eval set can overfit just as badly as your model. Evals for conversational agents need semantic judgment, not string matching. And 100% on a test suite is a warning sign, not a finish line.
Killing the latency
With behavior converging, we turned to the other complaint: the agent was slow. We identified six potential. We decided to go ahead with 3/6, dropping three of them with explicit reasoning. To be particular:
eager_eot_thresholdtuning - Doesn't apply to a managed voice agent architectureFiller speech before slow tool calls - caused a double-audio issue
Parallel function processing - An intentional safety measure.
Here's everything we actually changed, in roughly the order we did it:
Instrumentation first. Before optimizing blind, we built a per-call latency tracer. Basically, a waterfall showing every span per turn with contextvars-based propagation, so it worked across async boundaries. agent_thinking, fc:get_menu, menu:embed, menu:cache_lookup, fc:cart_add_item, first_audio_byte. All visible per call. Without this, we would have been guessing. With it, the bottlenecks were obvious within one call.
TURN 2: "hi i would like to get hot honey sandwich..."
>>> E2E latency: 5234ms <
agent_thinking + 12ms 12ms
fc:get_menu + 524ms 823ms
menu:embed + 524ms 312ms (all-mpnet-base-v2, CPU)
menu:cache_lookup + 573ms 387ms (Supabase pgvector)
fc:cart_add_item + 1348ms 487ms
* first_audio_byte + 5234ms
agent_speaking + 5234ms 1847ms
Oops.
The embedding model was catastrophically oversized. We'd been running all-mpnet-base-v2 (a 110M parameter, 768-dimensional model) on a CPU VPS, for a restaurant menu with a handful of items. No GPU, no quantization, just raw CPU inference. Encoding time was 30-80ms per query before we even touched the database. We switched to snowflake-arctic-embed-s33M parameters, 384 dimensions, 5-12ms encoding, and better retrieval accuracy for short domain-specific text. The right tool for the actual use case.
ONNX loading was broken in production. We'd been running a custom export/quantize flow in Docker that was silently failing due to optimum library detection issues. Switched to loading the pre-built model_O4.onnx directly from HuggingFace Hub. This eliminated the entire fragile export pipeline, removed ONNX_CACHE_DIR and EMBEDDING_QUANTIZE env vars, and the Dockerfile warmup step became a simple model download.
Embeddings moved into Redis. Even with the faster model, we were still hitting the embedding computation on every cold query. We moved the computed embeddings for menu items and FAQs directly into Redis. The same cache layer we were already using. No round trip to Supabase pgvector, no recomputation. Under 5ms for a cache hit vs 100-400ms for a Supabase vector search.
Redis read-through cache for all hot data. Menu, FAQ, and restaurant hours were being fetched from Supabase on every tool call. All three moved into Redis with a 24h TTL. Tool call data retrieval dropped from 100-400ms to under 5ms across the board.
Pre-warming on call connect. Even with Redis caching, the first call after a cold start still paid the full penalty. We fire a background asyncio.create_task the moment a call connects. The menu, FAQ, hours, and ONNX embedding warm-up are all running in parallel during the greeting window (~2-3 seconds). By the time the caller finishes saying hello, the cache is warm.
reasoning.effort=none on GPT-5.4-mini. Shaved 50-100ms off time-to-first-token. GPT-5.4-mini is a reasoning model by default. Turning off the reasoning step for a fast-response voice agent use case is an easy win.
max_completion_tokens raised from 200 to 500. This one wasn't a latency fix. It was a silent correctness bug that had been masquerading as one. In longer conversation turns, the model was hitting the token limit and truncating its response mid-sentence. Raising the cap fixed empty and cut-off responses in later turns entirely.
The tool calls decisiveness. The tool description rewrite (described earlier) had a latency payoff, too. Decisive tool selection means fewer round-trips and no hesitation loops.
The combined result: get_menu total latency went from 130-480ms down to roughly 6-18ms. End-to-end, the agent went from sluggish to snappy.
TURN 2: "hi i would like to get hot honey sandwich..."
>>> E2E latency: 1180ms <
agent_thinking + 10ms 10ms
fc:get_menu + 18ms 22ms
menu:embed + 18ms 8ms (snowflake-arctic-embed-s, ONNX)
menu:cache_lookup + 22ms 4ms (Redis)
fc:cart_add_item + 310ms 310ms
* first_audio_byte + 1180ms
agent_speaking + 1180ms 620ms
Not too shabby.
UUID hallucinations
Just when we thought behavior was converging, the client reported something new. The agent was speaking correctly (confirming the right items, the right quantities), but the actual order data didn't match. The cart contained the wrong things.
UUID hallucination rate was ~10% of tool calls. The agent confidently said "California Cobb Salad" while sending the UUID for a Korean BBQ Sandwich.
This one took a moment to understand.
The root cause was UUID confusion. Our menu items were identified by 32-character UUIDs internally. When the LLM called cart_add_item, it was selecting UUIDs from the menu — but sometimes picking the wrong one. The agent would say, "I've added the hot honey chicken sandwich" while actually sending the UUID for a California Cobb Salad. Confidently wrong.
The reason it had gone undetected: our tool responses only echoed raw UUIDs back to the LLM. No human-readable names. So when the model sent a wrong UUID, the response confirmed it without exposing the mismatch:
{
"cart": [
{
"item_id": "a3f9c821-4d2b-4e7f-9c1a-8b5d2e6f0341",
"quantity": 1
}
]
}
The feedback loop was broken. The LLM had no way to self-correct because it couldn't see its own mistake.
We tried three fixes before landing on the right one:
Shortened UUIDs to 8 characters — still hallucinated. The problem wasn't length.
Fuzzy matching with edit distance ≤ 2 — band-aid. Caught some corrupted IDs but masked the root cause.
Replaced UUIDs with human-readable slugs + returned resolved item names in tool responses. Now, when the LLM sends the wrong ID, the response exposes the mismatch.
{
"cart": [
{
"item_id": "hot-honey-chicken-sandwich",
"item_name": "Hot Honey Chicken Sandwich",
"quantity": 1
}
]
}
Now, if the model sends the wrong identifier, the response immediately surfaces the mismatch. The agent says "hot honey sandwich" but the response says "California Cobb Salad". That's a visible discrepancy, self-correctable on the next turn.
We also added a new eval assertion (expect_cart_state) that verifies actual Redis cart contents after each turn, independent of what the agent said out loud.
This resolved all five client-reported failure modes:
Wrong quantities in cart
Unreliable item deletion
Item substitution (asked for X, got Y)
Voice/cart mismatch (agent says one thing, cart has another)
Lost modifications (special instructions dropped)
On the prompt side, we did a significant cleanup at the same time: simplified from ~1500 to ~700 tokens, enforced comma-separated multi-item search terms for better embedding accuracy, and made order recap mandatory for all orders.
The max_completion_tokens bug we fixed during the latency pass (200 → 500) also surfaced here — truncated responses in longer turns had been masking correctness issues
After all of this: 13 eval scenarios, 7 perfect runs out of 8.
Two Prompts, one client
After everything, the nuclear option attempts, the agentic loop, the overfitting fail, the latency fine-tuning, the UUID fix, we had two viable agents sitting side by side.
The first was the organic prompt. It had evolved through dozens of agentic loop iterations, patched and shaped by the eval suite over hundreds of runs. Structurally chaotic, hard to read, cold, but battle-tested. The agent using it felt natural and conversational, and a little unpredictable in the way good conversation is.
The second was the XML state machine. Clean sections, explicit states, and every tool described with precision. Easier to maintain, easier to hand off, easier to reason about when something goes wrong. Nearly identical eval scores to the organic prompt, but a fundamentally different philosophy underneath.
Technically, we couldn't separate them. Both were hitting 13/13 consistently. Both handled the full scenario suite. There was no objective winner.
So we let the client choose.
We gave them both numbers, walked them through the difference in feel, and asked which one they wanted to live with. From an agency perspective, this is the right call. The client will be the one fielding complaints if the agent misbehaves six months from now. Their intuition about how it feels on a real call matters more than our eval scores at this point.
They tested both, they were ecstatic with the results, picked one and went live. The weekend was over.
Takeaways
Two days, only one topic in mind, tons of burnt tokens, and new knowledge about building agents. Here's what we'd do differently from day one and what we'd do exactly the same.
For agencies shipping AI products on third-party stacks:
Build the eval harness before you need it. When the regression hit, we had nothing to measure against. The first day was spent building the harness rather than fixing the agent. If it had existed already, we would have had a score within minutes of the incident and been iterating immediately. The harness paid for itself the moment the second incident hit.
Vendor-side drift is a real risk, and it's not yours to prevent, only to detect. You can't control when Deepgram or OpenAI updates their models. You can control whether you notice. An eval suite running on a schedule against production is your early warning system.
Managed abstractions earn their keep. The instinct to swap or rebuild when something breaks is expensive. Deepgram's managed stack handles barge-in, turn detection, audio buffering, and telephony plumbing. We only truly appreciated this when we tried to replicate it ourselves.
For engineers building voice agents:
Tool descriptions are architecture, not documentation. They are the primary signal the LLM uses to decide what to do. No conditional logic. No ambiguity. Clean, concise, unambiguous mappings. If your agent is hesitating or looping on tool selection, look here first.
Close the LLM feedback loop. If your tool responses only echo back opaque identifiers, the model can't self-correct when it makes a mistake. Return human-readable names alongside IDs. Make mismatches visible.
Right-size everything for the actual use case. A 110M parameter embedding model on a CPU VPS for a restaurant menu is not a reasonable choice. Neither is a 200 token completion limit for a multi-turn ordering conversation. Match your infrastructure to your problem, not to what you've used before.
Your eval set can overfit just as badly as your model. 100% on a test suite is a warning sign. Keyword matching breaks conversational evals. Use an LLM judge for text assertions and keep tool call assertions hard and exact.
max_completion_tokens will bite you silently in long conversations. Set it generously. The failure mode (truncated responses mid-sentence in later turns) looks like model behavior until you look at the logs.
The meta-lesson:
The Karpathy auto-research pattern works. Not just as a research curiosity, but a practical incident response tool. Give Claude Code a feedback signal, a clear scope, and permission to iterate, and it will find solutions you wouldn't have reached manually in the same time. The harness is the prerequisite. Without a reliable score, the loop has nothing to optimize against.
We came in expecting to fix a model drift issue. We left with a better-architected agent, a proper eval suite, a dramatically faster stack, and a pattern we'll use on every voice agent we build from here.